The GWDG offers data scientists various services and training courses to support them in their work throughout their entire workflow. As the success of a machine learning project often depends on the available computing resources, the working group „Computing“ operates various HPC systems with suitable accelerators to train deep learning models. This article explains model training using the highly energy-efficient HPC cluster „Grete“. The example is an excerpt from the course „Deep learning with GPU cores,“ offered every six months.
Introduction
The GWDG offers several services and trainings to support researchers in their machine-learning projects1. Deep Learning success is heavily compute-bound23; accelerators integrated into our HPC systems can help overcome this bottleneck. The GWDG offers several HPC systems4 with modern GPU nodes and other accelerators5 accessible to different user groups6. If you are wondering whether you have access to our systems, look at our science domains blog article from June 6. Additionally, the KISSKI project 7 is not limited to researchers, but small and medium-sized enterprises are highly welcome.
Further, we aim to support different science domains in the scope of the NHR alliance 8. Here we focus on researchers in the fields of artificial intelligence 9, digital humanities, bioinformatics 10, and forest science 11.
Machine learning workflow
A typical machine-learning workflow can be seen below (see figure 1). However, this article will only focus on model development and evaluation best practices. Regardless, the GWDG offers services to support you in every step of this workflow 1. If you need our assistance with anything, feel free to contact us.
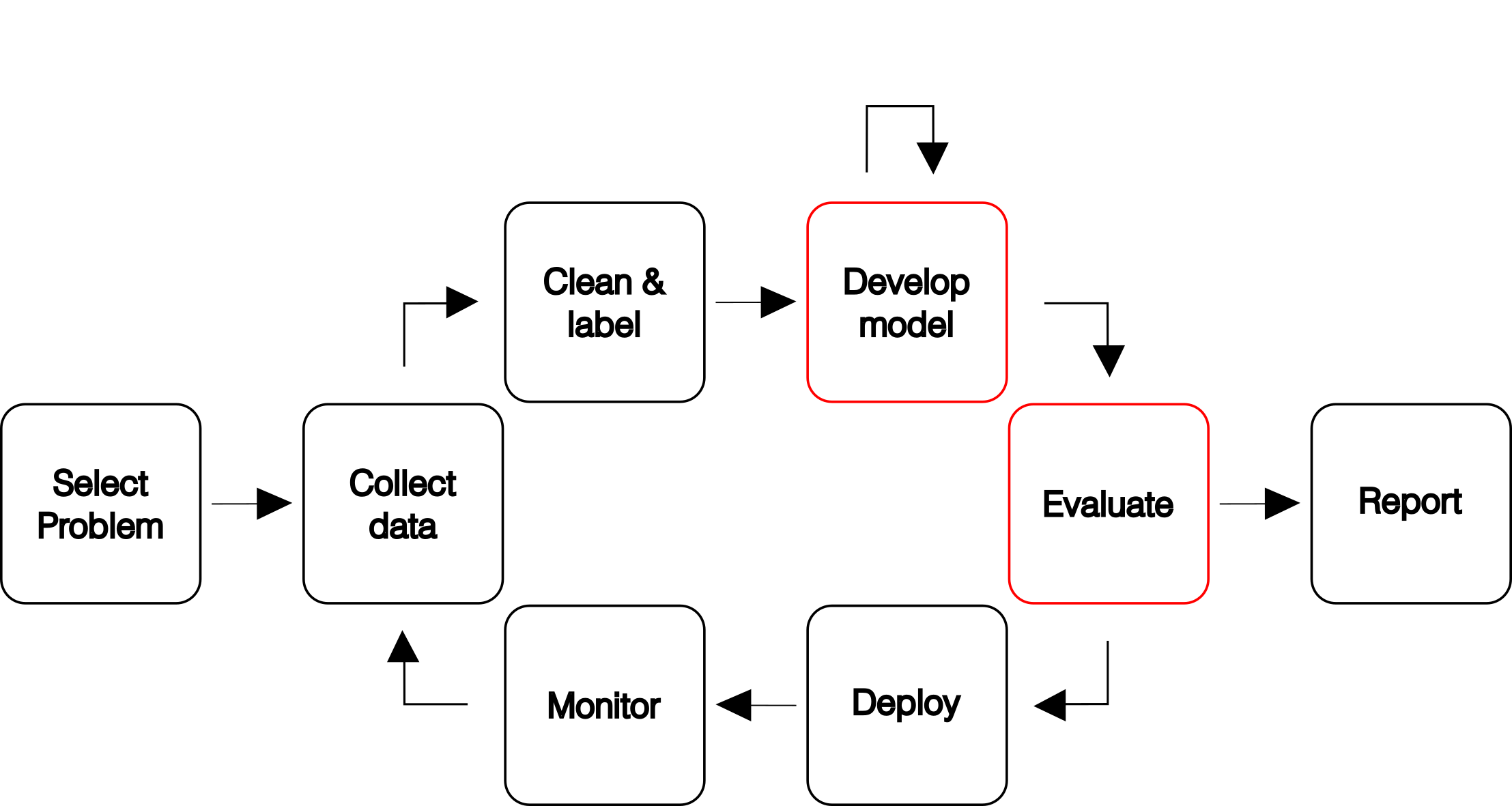
The figure is adapted from https://fullstackdeeplearning.com/course/2022/ .
HPC Cluster
A high-performance computing (HPC) cluster consists of different essential components, which are critical to understand to use its resources efficiently. Here, we will briefly explain the basic terminology. If you are interested in a more detailed article on this topic, please read our science domain blog article „What scientists should know to efficiently use the Scientific Computing Cluster“ 12.
First, a user can access the login node of the HPC cluster via an SSH (Secure Shell Protocol) connection (1 in figure 2).
In the example workflow below, you can see that glogin9 is the login node of our GPU system Grete13. On the login node, jobs are submitted with the job scheduler Slurm14 (2 in figure 2) A job on SLURM is a combination of which program you would like to run and which computing resources (hardware) you need. Compute nodes take care of the actual computing of your jobs, similar to your personal computer. Those compute nodes consist of cores and memory (RAM). Cores are processing units, such as CPU or GPU. Each node can have a different number of cores. Each node also has its own (temporary) random-access memory (RAM) used for temporary computations. Various storage systems with different characteristics help to handle and organize data efficiently (3 in figure 2). While using the shared scratch for your computation has great results, it is not great for long-term storage. This type of file system has no backup! However, your home folder has a backup. As indicated in the figure by the connection to the tape archive (right center). These are literal tapes that, after being written, are stored as physical components not connected to any electricity. Lastly, connecting S3 buckets to the whole cluster (bottom right) is also possible.
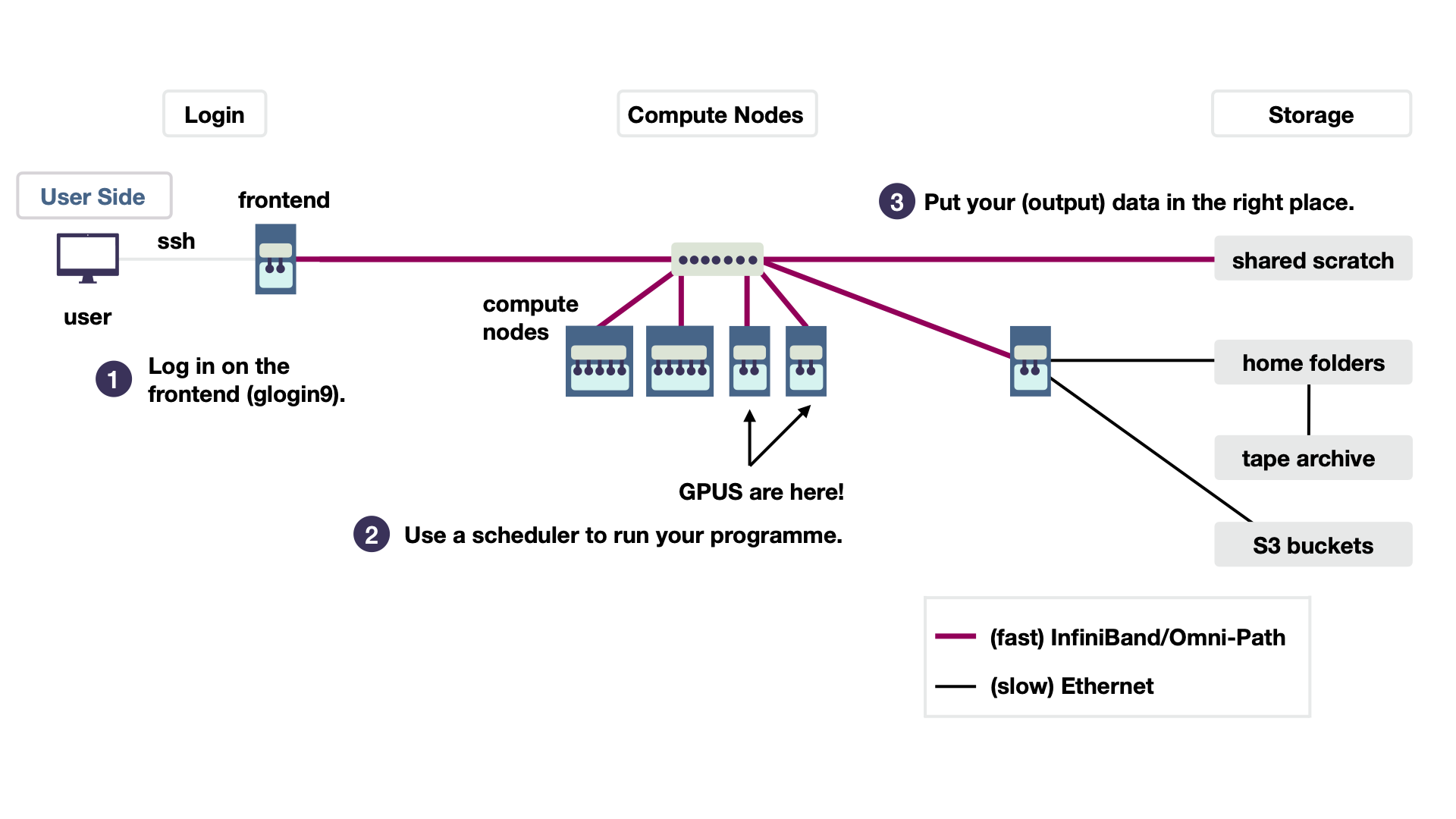
The figure was taken from our deep learning with GPU course offered every half year.15
Coding
In order to use the HPC resources, you will need to write code and develop programs. The programming language depends on the target application. For machine learning and deep learning, Python is often the best choice due to its moderate learning curve and availability of comprehensive packages and frameworks, such as PyTorch, JAX (with Flux) or Tensorflow.
Tools and Frameworks
For development, we recommend VSCode16 as it supports many features and programming languages including Python through its vast selection of extensions17. VSCode can also be configured to connect to the cluster directly which makes development simple and straightforward18.
When working on a Python project, it is best to use a virtual environment or container with a tool such as conda, singularity or apptainer19, to ensure reproducibility and robustness of the code, as packages are constantly updated and your code may require specific versions.
There are several widely-used frameworks for deep learning in Python. Three more common ones are PyTorch, TensorFlow, and JAX. Tensorflow is the first major deep learning framework and was developed by Google in 2015. PyTorch was developed in 2016 by Facebook, and is currently the most dominant framework in academia winning 77% of the competitions. JAX20 is a relatively new framework developed by Google that is aimed towards a more general auto-differentiation and vectorisation framework.
For most cases, we recommend using PyTorch.
Documentation and Code Handling
Code should be well-documented and clean; comments and README files should be included when necessary and repetitive code must be converted into functions and packages. It is also recommended to treat raw data as immutable; build the code around the data instead of editing the raw data itself. Cookiecutter is a tool that can get you started with a decent project structure and has some good recommendations as well21
It is crucial to use a Version Control System (VCS) such as git to avoid accidents and disasters when altering code and in general to gain better access and control over the code history. GWDG offers a GitLab server for this purpose. A good example is the deep learning with GPU workshop repository located in GWDG’s own GitLab server15.
Job Scheduling with SLURM
Running complex programs is forbidden on the login nodes. It is important to run complex tasks, e.g. data processing, model training and testing, only on the compute nodes. As mentioned before, the login nodes are strictly for low-cost tasks and job submission. You must use our job scheduler slurm to run jobs on the various nodes in the cluster. When submitting a job via slurm, you must set the job configuration, e.g. requested partition/node and GPUs, and you may also add additional settings such as the amount of RAM, time limit, email address to be notified when the job is complete, and a location to store the job’s log file produced by slurm. It is recommended to specify a location to store the log file and regularly check it for any issues. An overview of the configurations in SLURM can be found in our documentation 22.
During model development, you may want to run interactive jobs in the terminal with srun, e.g., for testing purposes. In this case it is better to use nodes in partitions designated for this use case such as grete-interactive. Finally, you may train the model by writing a slurm batch script and running it with sbatch on a dedicated GPU node, e.g. on partition grete. 23
You must also make sure that the requested node configuration is available and suitable for the job. For example, during development if the job is more likely to fail, it is better to set a low time limit and run the job on a test node if applicable. Similarly, the number of nodes and resources must be sufficient for your job while not being too excessive. It is better to split a long job into smaller jobs to avoid time limit issues and potentially wasting resources. To chain consecutive jobs with automated start and easier checkpointing we recommend snakemake24.
Monitoring
While your program is running, it is important to monitor the resource utilization on the nodes to identify bottlenecks, errors, and possible improvements.
CPU vs GPU
CPUs and GPUs are both powerful processing hardware that can perform complex calculations. Figure 3 depicts the inner structure of CPUs and GPUs. While CPUs are capable of handling a larger variety of instructions, GPUs are more efficient when it comes to specific simple instructions. It is important to know when using a GPU improves performance and when it does not.
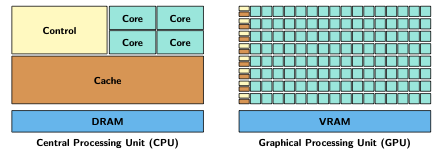
A thread is a series of sequential operations. A CPU is capable of processing multiple threads performing different tasks simultaneously. GPUs, on the other hand, are generally suitable for tasks that run the same operation on a large number of elements, i.e., running many similar threads at the same time.
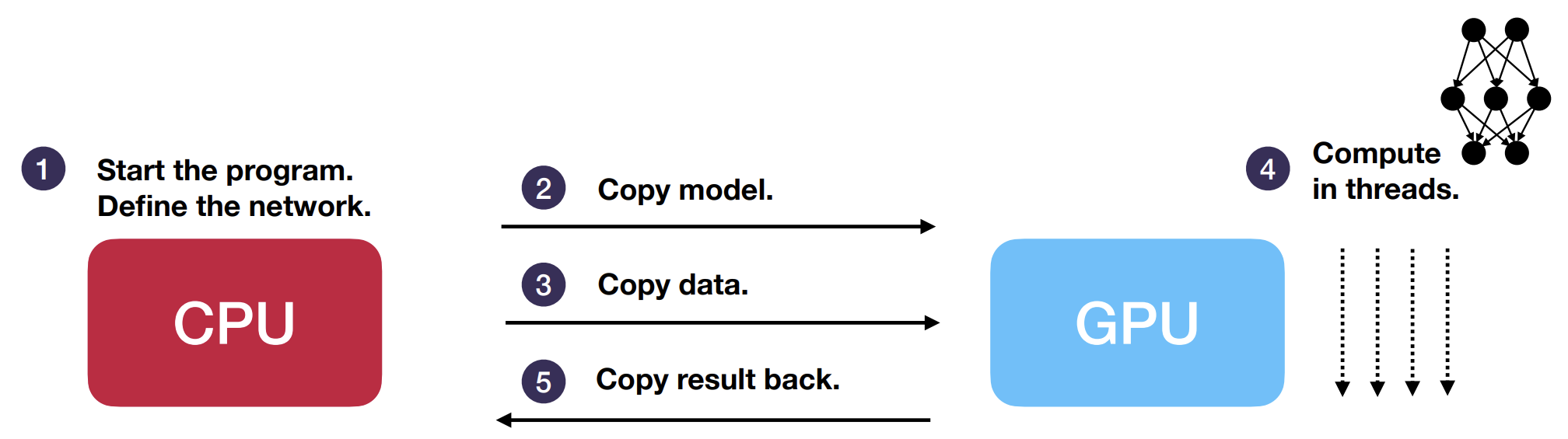
Figure 4. Role of CPU and GPU in typical deep learning task.
Figure 4 depicts a typical deep learning task running on a GPU node. The CPU is responsible for starting and running the program, beginning by initiliazing the model and storing it in the RAM. We would now like to take advantage of the GPU’s fast processing power in order to train the model, however, the GPU cannot directly access data stored in the RAM. Instead, it has its own memory (usually called VRAM, short for Video-RAM), which can vary in size depending on the GPU, but is typically smaller than the RAM.
During training, the model parameters and data must be copied from the RAM into the GPU’s VRAM. The GPU can then feed the input data into the model, compute the result, and update the model. The result may then be transferred back to the CPU for further processing.
Transferring data between the CPU and GPU is not immediate, and the time it takes should be taken into account. If the processing task is too simple, running it on a GPU would have little advantage over a CPU. To make full use of a GPU, you must ensure that lots of computation is performed on the GPU and the amount of data transfer is low in comparison. This can be verified using our recommended monitoring tools.
CPU and RAM Usage
It is possible to view the hardware resource usage of a node by simply logging into it and running top (for CPU nodes) or module load nvitop then nvitop (for GPU nodes) in the terminal.

A typical output of nvitop is shown in Figure 5. MEM depicts the amount of allocated GPU memory and UTL shows the GPU utilization. A constant low utilization of the GPU means that the GPU is mostly idle and waiting for more data.
The GPU memory should be large enough to support the model and batch of data simultaneously. There are different types of GPUs available on the cluster which can be selected depending on the use case. For newer GPUs, you may run your job on a GPU slice using NVIDIA-MIG when the full GPU power is not required. An overview of the available GPUs and usage can be found here: https://www.hlrn.de/doc/display/PUB/GPU+Usage
Example
An example of deep learning with GPU on the cluster and a recorded video series is available. 15 25
-
Both graphcore systems and neuromorphic chips are being acquired as part of the KISSKI project. ↩
-
https://gitlab-ce.gwdg.de/hpc-team-public/science-domains-blog/-/blob/main/20230623_hpc-access.md?ref_type=heads ↩ ↩2
-
https://gitlab-ce.gwdg.de/hpc-team-public/science-domains-blog/-/blob/main/20230417_cluster-practical.md ↩
-
https://gitlab-ce.gwdg.de/dmuelle3/deep-learning-with-gpu-cores ↩ ↩2 ↩3
-
https://info.gwdg.de/news/en/configuring-vscode-to-access-gwdgs-hpc-cluster/ ↩
-
https://gitlab-ce.gwdg.de/hpc-team-public/science-domains-blog/-/blob/main/20230907_python-apptainer.md?ref_type=heads ↩
-
https://www.youtube.com/playlist?list=PLvcoSsXFNRblM4AG5PZwY1AfYEW3EbD9O ↩
Author
Ali Doost Hosseini | Hauke Kirchner | Dorothea Sommer